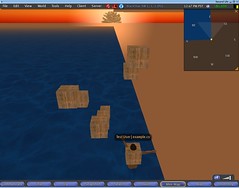
Texture sending code finally works - the stupid mistake was in the wrong assumption about the lower level. So now I can enjoy the strange tree-like sun. Moreover, after the peek at libsl the TextureEntry is somewhat done as well - so now the cubes are made of wood instead of some strange gray matter.
All of this has exposed a few interesting bugs in the lower-level code - timers/slists, which I seem to have found and fixed - although as can be clearly seen, the strings now look a bit like junk - because of the absent null terminator (which was being automagically added by the same code that caused the texture sending to fail). To make them show up quicker, I made a funny patch - which attaches a callback on every object being created and makes it float up to 10m, and then back to 1m, then up again.
Creating the masses of these has exposed another interesting dilemma, which will probably cause the tweak to the use of the simple slist crawlers for the object updates. The funny problem for now looks as follows: suppose I have 100 objects. All of them are with timer callbacks, so they *move* - and move often.
This results in the corresponding slist entries being deleted and reinserted at the tail of the update slist.
Due to the "pull" nature of the updates, if the update iterator moves not too far within one step - then this results in some objects never moving on the client - because by the time the iterator manages to walk to them, they are on the tail of the slist again... I'll need to prove this theory by adding the dynamically tweakable number of the updates sent within a single cycle, but it seems rather plausible.
The interesting question is how to do it in the least quirky way - one possible solution is to measure the frequency of the reinserts of the given object update node, and if the number is consistently high, to periodically leave a node lingering around marked as "secondary", and have a "cleanup" iterator slowly moving alongside the slist and wiping out the secondary nodes. So the slower clients have a chance to get the updates still.
Having the lowest speed of it bounded, would guarantee that the maliciously (or pathologically:) slow client can not stall the resources on the server by forcing it to create an infinitely long slist. Of course, the slow client will now have to pay a price of potentially getting the multiple duplicate updates as it moves along - but that is a fair price for keeping the data structure size O(1) instead of O(Nclients) for the case of the separate per-client queueing. Of course, premature optimization and all that - maybe it is simpler not to try to be smart and have a per-client "intelligent queues" - but assuming there are 200 clients, each object change implies the 200x work at once, and probably to throw away stuff for the majority of these... That's seems a bit too wasteful - and would kill the elegance of simply putting the newly connected client to crawl from the beginning of the object update slist...
Tuesday, April 29, 2008
Flying wooden cubes and the tree eclipse
New toys for the human :-)
I've been quite silent for a couple of weeks - mainly because of the human's RL trip to the US. Of course, this had a side of visiting some local gadget shops... And with the euro being expensive as it is... the human has gone slightly bananas and forgot that there was common sense. One of the nicest acquisitions was the Eeepc. In folded state it is quite exact to the A5 size - so it is really no bigger than most of the books - which proved to be a huge advantage in the airplane - alongside with the almost 3.5 hours of battery life. And in addition to the formfactor, the goodness one gets for approximately 350 euros (if all the math is right) is 1G of RAM, 8G of flash, wireless/ethernet, and the camera.
Now, here's the coolest part - it comes with Xandros linux preinstalled. So, even though the default desktop seemed kind of cute, the first thing indeed that was apt-gotten, was the fluxbox, gcc, git, openssl&co, and other practically pointless things. And i did not have to wipe out the whatever-other-OS-that-was-there-before and fiddle with the basics (kernel configure/compile is exciting only the first twenty times or so)
The first usage experiment shown that the human needs to compartmentalize the motoric memory responsible for typing (as now I tend to hit "F1" instead of "Esc"), and that the fingers are a bit too fat.
As a nice bonus, the beast auto-starts Amarok when it sees the iPod Nano connected to it. As a not-so-nice bonus the Amarok's song layout does not get recognized by iPod Nano, the only way I've solved that is by using the "standard means" aka iTunes on Windows.
The CPU is not a demon (only 600Mhz), and graphics seems to be not accelerated (so no SL, even though there's no point to run it as it would have been too slow) but having a familiar architecture in a size of a pocket book is very pleasing.
Monday, April 14, 2008
Objects, updates, and iterators
Today was the day of object updates. That is, writing the object updates.
The initial implementation is going to be very simple: an array of objects indexed by local id, and a queue of "local updates" with the members pointing towards which objects need to be updated. When the object gets updated, its reference moves to the end of this queue. Each agent periodically advances iterator on this queue as it sees fit, and sucks in the updates.
If there's a new connection - then its iterator is placed in the beginning of the queue, hence getting the updates for all the objects within the scene.
Indeed, polling an iterator for each agent seems like a lot of overhead - but I think it is not - what it would allow is the appropriate pacing of updates - slower clients would get the updates less frequently, and those would be more coarse. The faster clients will get the updates more as they come - hence will get smoother updates.
But there's one small detail - for this to work, the iterator implementation needs to be flawless. Which apparently is totally not the case :-)
Looks like I need to sit and write what happens in each specific scenario - otherwise it is a very good recipe to spaghetti code.
Sunday, April 13, 2008
What would you do if you found a card in the ATM ?
The human today had a very interesting experience. Imagine you come to the ATM, and find that some poor soul has rushed to grab the money so much that they forgot their card in it... Quite odd. Interestingly enough, the first thought was "hmm this is totally insecure - with the card in the ATM - it needs to go out *now*". Then standing with the card you do not own, and figuring out what to do next...
Wait to see if the person comes back ? highly unlikely - the things like this usually go unnoticed until the next time one needs the cash. Destroy the card ? that's not good either... Call the service to stop the card ? Probably a reasonable idea, but unwinding that would involve a bit of legwork for the poor soul with bad memory. Nonetheless, waiting for a few minutes - and indeed no-one showed up...
Luckily the scene was a " booth on bank's premises" - it's common in Brussels to have such a thing - and the closed glass entrance door into the bank was just a couple of meters away.
So - the card went under the door - some 50 cm from it, inside the bank - visible from outside, but practically inaccessible until the bank's staff opens the branch tomorrow. And if the person realizes and comes back - there are chances they will see the card and can pick it up in the morning morning from the bank without too much hassle. Else the bank staff will take care of it. I hope.
user database, activerecord, and extension to HTTP
Today was mostly about figuring out the intricacies of the certificate generation in openssl, and wrapping them into the appropriate Ruby code - and a bit of standalone ActiveRecord coding.
As a result, I now have the module, that implements PKI in a way that allows to operate it without the major headache:
uca = UCA::UCA.new([ ["CN", "Test CA" ] ],
"Test CA", Proc.new { |flag| "test" })
u = User.new
u.firstname = "Dalien"
u.lastname = "Talbot"
cn = [ ["CN", u.firstname + "_" +
u.lastname + "@" + 'localhost' ] ]
rsa, csr = UCA::Utils::generate_csr(1024, cn)
cert = uca.sign_csr(csr)
u.rsa_cert = cert.to_pem
u.rsa_key = rsa.export(
OpenSSL::Cipher::DES.new(:EDE3, :CBC), "test" )
u.save!
This small fragment of code creates the user, initializes a tiny CA, and creates a new user record with the certificate signed by this CA.
Now, in the previous post about groups, presence, etc. I was thinking about nice half-persistent connections between the presence servers. HTTP would not necessarily fit there unless I'd be interested to make two unidirectional connections - which is boring.
So, the other part of the fun was figuring out the way to do it in a simplest way, such that I could reuse the webrick as much as I can... And I think I found a pretty fun hack to do it - CONNECT method.
There's an old draft which somewhat describes this method, and from what I know, de-facto it is implemented (even though I could not find the published RFC describing it).
I'm (ab)using this method to provide the "direct connection" between the two stream-oriented applications on client and server. As soon as the server replies with the standard HTTP reply "200 OK" - the two endpoints on the client and the server are connected with asynchronous stream, and can send the data to each other whenever they want. The only difference between the "classic" usage and mine is that I will probably use the URI in lieu of hostname:port - which will describe the point to connect to on the server. (especially since obviously the server would not tunnel the connection anywhere further).
It's a bit of arm-twisting, but seems to integrate quite nicely both with webrick and the C code that I have. And since the stream will be SSL-encrypted anyway - noone should care.
Obviously the process of "short-circuiting" will need to take into the account the certificates presented by both sides, and possibly establish the ACL/QoS based on that.
Also, the Ruby code got an excellent UUID library, so now both the C and Ruby can generate the mac-based UUIDs.
Update:
on a second thought, the "CONNECT" idea is quite a bad one. The end result is that the code on both sides will have to demultiplex the flow of data in two different directions - which adds the complexity and bugs... So it will be put into a box for now.
Saturday, April 12, 2008
New toysand the effects
Ciaran writes about the new toy in progress.
I'll copy in the embedded Youtube video here, because it's pretty cool:
While I wholehartedly adore the neatness of this - what makes me wonder is the ergonomics of such a steering - an almost static standing position (especially leaning forwards and backwards) - looks like a good recipe for various muscular problems... Or not ?
Tuesday, April 8, 2008
Thoughts on presence, chat, and groups...
Even though it's pretty much early for this, I've started to muse more in detail about scaling the chat/presence/identity thing. I think it's actually pretty straightforward if we introduce the concept of "home server" - a place where the avatar "belongs". This does not have to be a sim as such - since these activities are not necessarily related to the 3d presence.
A user would have a "home identity server" - something that they trust enough to hold the private key of the avatar, and authorize the signing / encryption operations using this key. This server would house also their "profile" - something that holds the pointers to the their "home inventory server", "home message server", "home presence server", possibly even "home physics server" (even though at current the distributed physics is probably out of the question, one should not assume it will always be like this). The "publicly viewable" profile would also hold the offline contact mail - dedicated to the communications when "off-line".
Then a lot of things become quite easy. Let's take a look at presence. If I add you to my contact list, all I have to do upon my login is to have my home presence server contact the home presence servers of my contact list and notify them that I am online - then they can update the state of the contact lists for the folks who are based there - and correspondingly to let my presence server know in return which of my contacts are online. Assuming the "friendship" link between the presence servers is protected by a shared key specific for this link, it will be rather difficult to spoof - as well as to get an unsolicited presence queries, unless explicitly permitted.
Of course, then revoking the "friendship" is also possible by either of the sides - you just invalidate the shared key for that link, and then the matter of
unsolicited queries reduces to a classic problem of fighting off the DoS against a website - which, although it is a difficult problem, has already received enough attention and has some solutions.
IMs are again trivial - my chat server knows who is online and who is not from the presence server, and can either relay the message to the contacts' chat servers or directly send it to them via their contact email in case they are offline. What's nicest is that then it is only the two servers - those of the sender and of the recipient - participating in the process, so this should scale pretty well as the number of "providers" go up.
Groups then could become just an special abstraction of "contact list" - with the difference that it would act more in a hub-spoke fashion - the members would send their presence / chat data to this server, and it would be the group server authorizing (or not!) chat in the groups, or providing this right to only a few people, etc.
These "contact list records" stored in the friends list / groups could hold some more interesting stuff - e.g. does this user allow the inventory offers from members of the given group, or from its contacts. Of course, the final permission check would be done on the recipient's servers - but putting the signed info as close to the source as possible, it would allow to prevent the waste of resources amongst the "well-behaved" servers.
And again - the protection from the ill-behaved servers reduces to countering a DoS from an untrustworthy source.
I'm pretty sure this is all doable with a little bit of PKI+shared secret+SSL woodoo.
The only (possibly large for some) drawback that I see is the need to expose an email address into the "identity profile" - which needs to be tackled. But the exposing of the email address only makes it resilient in the case of the server-side problems - i.e. in the case of IM, if your chat server could not contact my chat server (which was brought down by a vicious admin), then it would send an email using the exposed mail address.
Nothing prevents from just allocating a "VW-only" email address on the chat server (or its mail-handling counterpart) itself - then the server failures will only cause the delayed delivery of the IMs, but not a total failure. Probably that's the best way.
And given that your home chat server might allocate more than one email - say, one per contact, it would become quite easy to sort/prioritize the email-based IMs. And possibly even request the sent messages be signed by the sender + have the sender's profile attached - this way one can verify their authenticity, and store the state within the message itself.
Are average faces beautiful ?
Ok, time for a relaxing post to just waste your time :-)
On one of the /. discussions I've found a nice link: you can check out the experiment that showsthe average faces of humans. The idea is simple - they have a bunch of photos, you select those that you want to "average together", and judge the result. The common theory is that the most "average" faces are considered the most beautiful. (Although I guess the technical details on how to actually "average" the pictures must be less than simple, unfortunately the page with the "computer graphics methods" seems to be not present :(
Highly entertaining, and indeed the "averaged" results seem to be more aesthetic - albeit they seem more artificial - and the perception is - younger ? A very odd effect.
It's pretty tough for me to judge the attractiveness of averaging the guys' "averaged" faces - maybe some of the female avatars reading this blog might spare their opinion ? (Of course, I assume there are still left those that did not get scared off by my recent flurry of the half-coherent geek blabber :-)
Monday, April 7, 2008
Consoles, sessions, sockets and other stuff
Safe lists slowly got some code, as per this post, and I needed to test the code... However, I am slowly getting annoyed with the impossibility to dynamically tweak the debug levels.
Hence, I used the excuse of debugging the slist code to implement stupid console service - very simple, using openssl s_client (it does not provide the fancy terminal emulation, and at the moment there is no authentication (yuck!) - but it serves its purpose.)
The presence of the "console" code allowed to start playing with various commands - first one of course was to enable/disable debugging, and then there was some lower-level stuff, like the ability to show the sockets which
are being handled at this moment:
So, here's how it looks so far:
cosimus> show sockets
Running command 'show sockets'
Sockets:
0:tcp do_ssl:0,ssl:0,listen:1,lport:2323 remote: 0.0.0.0:0 fd:3 revents:0
1:udp do_ssl:0,ssl:0,listen:1,lport:9000 remote: 127.0.0.1:28032 fd:4 revents:0
2:tcp do_ssl:0,ssl:1,listen:0,lport:0 remote: 0.0.0.0:0 fd:6 revents:1
3:udp do_ssl:0,ssl:0,listen:1,lport:9000 remote: 127.0.0.1:28288 fd:7 revents:0
4:udp do_ssl:0,ssl:0,listen:1,lport:9000 remote: 0.0.0.0:0 fd:8 revents:0
cosimus>
Simple and stupid, but serves its purpose.
As we can see, also now there is a rudimentary code to understand the concept of client sessions - such that it was possible to hook up the update routine based on the slist of the local objects (aka lobjects, for short :)
6242 lines of code, if not to count the bazillion of auto-generated stuff.
Friday, April 4, 2008
Evolution vs intelligent design..
Normally I would not write about the things of this type, but I figured it is a cool oddness worth mentioning: apparently, on MS Windows you can make the "echo" command not interpret its arguments by appending the dot to it. So, the "echo. /?" outputs the "/?".
Don't rush to blame anyone - because the blog entry itself has an interesting ending - which is one of the reasons I think it was worth mentioning here:
"This is what happens when a language develops not by design but by evolution."
I'd put it a bit in a different way though - "This is what happens when the evolution of the language is not foreseen by the original design". The key thing is to try to not make the flexibility at a price of a complexity. On the other hand, it's amazing what one can do using the free tools out there. I've used the snacc at some point in time - it's a pretty cool beast. Albeit, I must admit that reading up about all those different kinds of seemingly overengineered things is probably a bit daunting. Of course, there's XML and all these newly derived formats...Boo. Too many angle brackets :)
Nonetheless, all of those are just special cases of distorted S-expressions :-) - so designing in terms of those might be actually the best approach.
So, I'll go off to install Lisp, and meantime you can go and read some wizdom.
p.s. Of course, any wizdom is subjective :-) - so don't forget to have other views as well :)
Wednesday, April 2, 2008
A missing sunset
I managed to get the sun texture cleaned away off my cache, and I did not fix up the texture sending yet. The notion of the missing sun was quite funny, so I figured I'd make an attempt to do some sort of "arts" about it :-)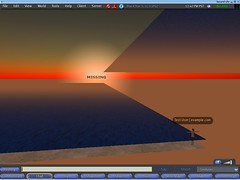
(BTW - the blue field on the right is "the water at its default level" :) Feels funny to experiment with the world of no physics and discontiguous water surfaces :-) (oh, and non-moving nudist avatars, for that matter:-)
Tuesday, April 1, 2008
Life is like a zebra...
Veyron posts a sad story with projections of the future. Reading it, I remembered an old anecdote, which I enjoy.
Two old friends meet each other:
1: how are you ?
2: all right, the business is flourishing, I just bought a new villa, I have a great wife and wonderful smart kids. And yourself ?
1: totally bad, my wife has run away from me with a circus clown, I have no job, and I am in a total distress...
2: don't worry - life is like a zebra - there are always stripes - black stripe, then white stripe, then black stripe, and then always white stripe again - so just keep going!
The same pair of folks meets some time later:
2: so - how is it going now ?
1: you know what... your saying about life being like a zebra... it was so true... Except, last time when we talked - it was actually a white stripe...
Conclusion#1: it can and will always become worse than now.
Conclusion#2: enjoy and value what you have while it lasts.
Argh. Looks like I did not really succeed in making a humorous post, did I ? :-)
Safe lists with iterators - useless musings about the data structures
While thinking about making the cubes persistent, and keeping in mind my bug within the list code, I came to a conclusion that to have any sort of iterators, the pointer/malloc based lists will be more a nuissance than help, so I have to come up with something that would encourage a more productive programming pattern.
I liked the feeling I got while coding the allocator for the timer structures, so decided to reuse this "generation+index" model once more - this time for lists.
How ? Each list essentially is managed as a resizable array of element structures. Each element is either allocated or is free. If it is free - then it belongs to the free list, and further discussion about working with it is quite boring - it is a simple unidirectional list, with the new elements grabbed from its head, and the newly freed elements being put onto its tail. But it is much more interesting to think about the allocated entries.
Each entry has a lock count - which greatly simplifies the iterator creation - simply increment the lock counter, and return the index (and element generation, of course). Then the "get_next" iterator will retrieve the "next" index from this list item, decrement the lock count, and it if is zero - then return the element to the free list.
There's only one "but" in all this: the explicit deletion of the element.
Suppose we have the list:
A->B->C->D
we start walking the list, and end up at B - whose index is stored elsewhere - so the picture will look like this: (the number of brackets is the number of locks):
(A)->((B))->(C)->(D)
Now we need to "delete" the item B explicitly and requeue it to the end of the list... So the structure now looks like:
(A)->(C)->(D)->(B')
(B)->(C)
Theoretically all is great - however, now assume the worst-case scenario that we also need to delete and requeue "C"... so we end up with this situation:
(A)->(D)->(B')->(C')
(B)->C
The "C" is now freed - so technically speaking it is undefined - so the get_next iterator will fail...
The way out of this might be to have the locks done only for the iterators use, and check the "previous" item's lock in case of deletion. Then the whole exercise will be done as follows:
1) after the first yield:
A->(B)->C->D
2) after the deletion of B:
A ->C->D->B'
(B)->C
3) now when we attempt to delete and requeue C, on the picture it is all nice... we need to check if there exists an "iterator-locked something" - like B in this case. Except the only small problem - C only has one "prev" index - so the only thing it knows about is A...
Ok, take 2 - we lock "this" and "next" items for the purposes of iterator, so the picture is:
1) after the first yield:
A->(B)->(C)->D
2) after the deletion of B:
A ->(C)->D->B'
(B)->(C)
3) after the deletion of C:
A->D->B'->C'
(B)->(C)->D
All looks great, except now we also would like to delete "D" - which brings us to the problem in the previous example!
However, I think there is still a way out.
Upon the request to delete the "iterator-locked" node, the next node also needs to be "iterator-locked":
1) after the first yield:
A->(B)->C->D
2) delete the B:
A->(C)->D->B'
(B)->(C)->D
3) delete the C:
A->(D)->B'->C'
(B)->(C)->(D)
Intuitively, this approach should prevent the need to find back "the nodes who refer to the node being deleted". Although, of course if has a big drawback - the iterator will need to walk all of the deleted nodes - with allegedly much more recent versions available at the end of the list - so these should be skipped. Which, in case of a large interval between the executions of the iterator and the massive updates to the list, will cause an excessive CPU cycles while skipping the empty elements. Which could probably be ok - I just might need to add a special case - "tried to skip the dead elements, but too much junk in the way - try again later".
