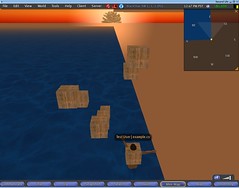
Texture sending code finally works - the stupid mistake was in the wrong assumption about the lower level. So now I can enjoy the strange tree-like sun. Moreover, after the peek at libsl the TextureEntry is somewhat done as well - so now the cubes are made of wood instead of some strange gray matter.
All of this has exposed a few interesting bugs in the lower-level code - timers/slists, which I seem to have found and fixed - although as can be clearly seen, the strings now look a bit like junk - because of the absent null terminator (which was being automagically added by the same code that caused the texture sending to fail). To make them show up quicker, I made a funny patch - which attaches a callback on every object being created and makes it float up to 10m, and then back to 1m, then up again.
Creating the masses of these has exposed another interesting dilemma, which will probably cause the tweak to the use of the simple slist crawlers for the object updates. The funny problem for now looks as follows: suppose I have 100 objects. All of them are with timer callbacks, so they *move* - and move often.
This results in the corresponding slist entries being deleted and reinserted at the tail of the update slist.
Due to the "pull" nature of the updates, if the update iterator moves not too far within one step - then this results in some objects never moving on the client - because by the time the iterator manages to walk to them, they are on the tail of the slist again... I'll need to prove this theory by adding the dynamically tweakable number of the updates sent within a single cycle, but it seems rather plausible.
The interesting question is how to do it in the least quirky way - one possible solution is to measure the frequency of the reinserts of the given object update node, and if the number is consistently high, to periodically leave a node lingering around marked as "secondary", and have a "cleanup" iterator slowly moving alongside the slist and wiping out the secondary nodes. So the slower clients have a chance to get the updates still.
Having the lowest speed of it bounded, would guarantee that the maliciously (or pathologically:) slow client can not stall the resources on the server by forcing it to create an infinitely long slist. Of course, the slow client will now have to pay a price of potentially getting the multiple duplicate updates as it moves along - but that is a fair price for keeping the data structure size O(1) instead of O(Nclients) for the case of the separate per-client queueing. Of course, premature optimization and all that - maybe it is simpler not to try to be smart and have a per-client "intelligent queues" - but assuming there are 200 clients, each object change implies the 200x work at once, and probably to throw away stuff for the majority of these... That's seems a bit too wasteful - and would kill the elegance of simply putting the newly connected client to crawl from the beginning of the object update slist...
Tuesday, April 29, 2008
Flying wooden cubes and the tree eclipse
![]()
Subscribe to:
Post Comments (Atom)

No comments:
Post a Comment